![]()
Pass Databricks Databricks Certified Machine Learning Professional Exam in First Attempt Guaranteed Updated Dump from ValidVCE!
Pass Databricks-Machine-Learning-Professional Exam with 193 Questions - Verified By ValidVCE
NEW QUESTION # 112
A data scientist is building a model to predict which communication channel (Phone, SMS, Email, or Post) is most likely to be effective for a given customer. Which model type is suited to this task?
- A. Logistic Regression
- B. Softmax Classifier
- C. Linear Regression
- D. ARIMA
Answer: B
Explanation:
This task requires predicting one class from multiple mutually exclusive categories. A softmax classifier is designed for multiclass classification problems and outputs a probability distribution across all possible communication channels, allowing selection of the most likely effective channel.
NEW QUESTION # 113
A data scientist has developed a scikit-learn random forest model model, but they have not yet logged model with MLflow. They want to obtain the input schema and the output schema of the model so they can document what type of data is expected as input.
Which of the following MLflow operations can be used to perform this task?
- A. mlflow.models.schema.infer_schema
- B. There is no way to obtain the input schema and the output schema of an unlogged model.
- C. mlflow.models.Model.get_input_schema
- D. mlflow.models.Model.signature
- E. mlflow.models.signature.infer_signature
Answer: A
NEW QUESTION # 114
Which component manages model versions?
- A. MLflow Tracking
- B. Model Registry
- C. Feature Store
- D. Spark ML
Answer: B
Explanation:
Model Registry handles:
versioning
stage transitions
governance.
NEW QUESTION # 115
A Machine Learning Engineer has previously built a feature table for model training and inference using a batch mode approach:
They have been informed that they now require these features to be available in "real-time", with latency on the order of a minute. Their manager has informed them there is now a Kafka stream from which they can stream live data, and they need to have this ingested and available for low- latency feature lookups.
Which change to their existing code will achieve this?
- A. Change the incoming_df to be a dataframe based on a readStream() from the Kafka source and publish the table as an online table with the streaming option set to True.
- B. Create a custom pyfunc MLflow model which processes results of the Kafka stream for on demand feature calculation.
- C. Change the incoming_df to be a dataframe based on a readStream() from the kafka source, the write_table() method will provide a low-latency lookup on this data.
- D. Run a triggered workflow to ingest the Kafka data to a dataframe that they can use with their existing write_table() command.
Answer: A
Explanation:
To achieve real-time availability with minute-level latency, the feature data must be continuously ingested from Kafka and published to an online table. Using a streaming DataFrame created with readStream from the Kafka source and enabling the online table with streaming allows incremental updates to be synchronized to the online store, supporting low-latency feature lookups for real-time inference.
NEW QUESTION # 116
A machine learning engineer needs to select a deployment strategy for a new machine learning application. The feature values are not available until the time of delivery, and results are needed exceedingly fast for one record at a time.
Which of the following deployment strategies can be used to meet these requirements?
- A. Real-time
- B. Streaming
- C. Batch
- D. None of these strategies will meet the requirements.
- E. Edge/on-device
Answer: A
NEW QUESTION # 117
A Data Scientist is developing a model training pipeline on Databricks and needs to track custom performance metrics during training. They want to log a custom evaluation score (team_score), a single hyperparameter, and a confusion matrix plot as part of their MLflow experiment. Which code snippet correctly logs all three types of information in MLflow?
- A. mlflow.log_param("max_depth", 5)
mlflow.log_metric("team_score", 0.92)
mlflow.log_artifact(open("confusion_matrix.png")) - B. mlflow.log_metric({"team_score": 0.92})
mlflow.log_param(["max_depth", 5])
mlflow.log_file("confusion_matrix.png") - C. mlflow.log_param("max_depth", "5")
mlflow.log_metric("team_score", "0.92")
mlflow.log_artifact("confusion_matrix.png") - D. mlflow.log_param("max_depth", 5)
mlflow.log_metric("team_score", 0.92)
mlflow.log_artifact("confusion_matrix.png")
Answer: D
Explanation:
This snippet correctly uses MLflow's APIs to log each item in its expected form: a single hyperparameter with log_param, a numeric custom metric with log_metric, and a file-based artifact such as a confusion matrix image by passing its file path to log_artifact. This is the standard and correct way to track parameters, metrics, and artifacts in an MLflow experiment.
NEW QUESTION # 118
A data scientist has created a Python function compute_features that returns a Spark DataFrame with the following schema:
The resulting DataFrame is assigned to the features_df variable. The data scientist wants to create a Feature Store table using features_df.
Which of the following code blocks can they use to create and populate the Feature Store table using the Feature Store Client fs?
- A.

- B. features_df.write.mode("fs").path("new_table")
- C.

- D.

- E. features_df.write.mode("feature").path("new_table")
Answer: D
NEW QUESTION # 119
A data scientist has created a Python function compute_features that returns a Spark DataFrame with the following schema:
The resulting DataFrame is assigned to the features_df variable. The data scientist wants to create a Feature Store table using features_df.
Which of the following code blocks can they use to create and populate the Feature Store table using the Feature Store Client fs?
- A. features_df.write.mode("fs").path("new_table")
- B.

- C.

- D. features_df.write.mode("feature").path("new_table")
- E.

Answer: E
NEW QUESTION # 120
A data scientist has computed updated feature values for all primary key values stored in the Feature Store table features. In addition, feature values for some new primary key values have also been computed. The updated feature values are stored in the DataFrame features_df. They want to replace all data in features with the newly computed data. Which of the following code blocks can they use to perform this task using the Feature Store Client fs?
- A.

- B.

- C.

- D.

- E.

Answer: E
NEW QUESTION # 121
A machine learning engineer has a machine learning pipeline where predictions are updated annually. The final prediction dataset contains millions of rows, and that dataset is irregularly accessed. Which solution should the machine learning engineer use to maintain cost efficiency?
- A. Cloud-based object storage
- B. Cloud-based low latency database
- C. On-premises low-latency database
- D. Cloud-based in-memory instance of a Spark DataFrame
Answer: A
Explanation:
For data that is large in size, infrequently accessed, and updated only periodically, cloud-based object storage (such as AWS S3, Azure Blob Storage, or Google Cloud Storage) is the most cost- efficient option. It offers durable, scalable, and inexpensive storage compared to in-memory or low-latency databases, which are optimized for frequent access and real-time performance rather than long-term, infrequent retrieval.
NEW QUESTION # 122
A Data Scientist at an online gaming company is creating a model to predict player churn. The company currently collects terabytes of player activity logs daily, which are stored in Databricks and processed for daily reporting. The Data Scientist has completed feature engineering and the resulting data is saved as a Delta Table with a size of 500GB. They need to next build the model for the most performant and cost-effective performance for Databricks. Which approach will do this?
- A. Load the feature data as a Spark DataFrame and train the model using SparkML's RandomForestClassifier on a multi-node Databricks cluster.
- B. Load the feature data as a Spark DataFrame and train the model using Spark's DeepspeedTorchDistributor on a multi-node Databricks cluster.
- C. Load the feature data as a pandas DataFrame and train the model using scikit-learn's RandomForestClassifier on a single-node Databricks cluster.
- D. Load the feature data as a pandas DataFrame and train the model using scikit-learn's RandomForestClassifier on a multi-node Databricks cluster.
Answer: A
Explanation:
A 500GB Delta Table is far beyond what is practical to load into a single pandas DataFrame, and scaling pandas-based scikit-learn training across nodes is not the right fit for this workload. Using a Spark DataFrame with Spark ML's RandomForestClassifier leverages distributed data processing and distributed model training on a multi-node cluster, which is the most performant and cost-effective approach for large tabular datasets in Databricks.
NEW QUESTION # 123
Which of the following is a benefit of logging a model signature with an MLflow model?
- A. The model can be deployed using real-time serving tools
- B. The model will have a unique identifier in the MLflow experiment
- C. The schema of input data can be validated when serving models
- D. The schema of input data will be converted to match the signature
- E. The model will be secured by the user that developed it
Answer: D
NEW QUESTION # 124
Which of the following is an obstacle related to streaming machine learning applications?
- A. All of these
- B. Out-of-order data
- C. End-to-end fault tolerance
- D. None of these
Answer: A
Explanation:
Streaming machine learning applications face multiple challenges, including end-to-end fault tolerance (ensuring recovery from failures without data loss) and out-of-order data (handling events that arrive late or out of sequence). Both are common obstacles in building reliable real- time ML systems.
NEW QUESTION # 125
A machine learning engineer is manually refreshing a model in an existing machine learning pipeline. The pipeline uses the MLflow Model Registry model "project". The machine learning engineer would like to add a new version of the model to "project". Which MLflow operation can the machine learning engineer use to accomplish this task?
- A. The machine learning engineer needs to create an entirely new MLflow Model Registry model
- B. mlflow.register_model
- C. MlflowClient.get_model_version
- D. mlflow.add_model_version
- E. MlflowClient.update_registered_model
Answer: E
NEW QUESTION # 126
A machine learning engineer is migrating a machine learning pipeline to use Databricks Machine Learning. They have programmatically identified the best run from an MLflow Experiment and stored its URI in the model_uri variable and its Run ID in the run_id variable. They have also determined that the model was logged with the name "model". Now, the machine learning engineer wants to register that model in the MLflow Model Registry with the name "best_model".
Which line of code can they use to register the model to the MLflow Model Registry?
- A. mlflow.register_model(f"runs:/{run_id}/model")
- B. mlflow.register_model(f"runs:/{run_id}/best_model", "model")
- C. mlflow.register_model(model_uri, "model")
- D. mlflow.register_model(model_uri, "best_model")
- E. mlflow.register_model(run_id, "best_model")
Answer: D
NEW QUESTION # 127
A machine learning engineer has developed a model and registered it using the FeatureStoreClient fs. The model has model URI model_uri. The engineer now needs to perform batch inference on customer-level Spark DataFrame spark_df, but it is missing a few of the static features that were used when training the model. The customer_id column is the primary key of spark_df and the training set used when training and logging the model.
Which of the following code blocks can be used to compute predictions for spark_df when the missing feature values can be found in the Feature Store by searching for features by customer_id?
- A. fs.score_batch(model_uri, spark_df)
- B. df = fs.get_missing_features(spark_df, model_uri)
fs.score_batch(model_uri, df)
df = fs.get_missing_features(spark_df) - C. fs.score_model(model_uri, spark_df)
- D. fs.score_batch(model_uri, df)
- E. df = fs.get_missing_features(spark_df, model_uri)
fs.score_model(model_uri, df)
Answer: A
NEW QUESTION # 128
A data scientist has written a function to track the runs of their random forest model. The data scientist is changing the number of trees in the forest across each run. Which of the following MLflow operations is designed to log single values like the number of trees in a random forest?
- A. There is no way to store values like this.
- B. mlflow.log_artifact
- C. mlflow.log_model
- D. mlflow.log_param
- E. mlflow.log_metric
Answer: E
NEW QUESTION # 129
A Machine Learning Engineer is building a Databricks ML pipeline to predict customer churn. The pipeline needs to include automated feature engineering, model training, evaluation, and deployment to a REST API endpoint using MLflow. What is the primary goal of an integration test for this pipeline?
- A. To monitor the model's performance after it has been deployed into the production environment
- B. To ensure that the pipeline's performance meets latency and scalability requirements under simulated production loads
- C. To verify that the pipeline can process a variety of data formats, even if some stages are skipped or bypassed
- D. To ensure the pipeline runs with all components working together and data flowing correctly between stages
Answer: D
Explanation:
The primary purpose of an integration test is to validate that all components of the ML pipeline work together as expected. This includes confirming that data flows correctly through feature engineering, training, evaluation, and deployment steps, ensuring the end-to-end pipeline functions properly as a cohesive system.
NEW QUESTION # 130
A Data Scientist is building a machine learning pipeline to classify raw text using a Logistic Regression model in Spark using Spark MLlib's Pipelines. This pipeline has three stages: the Tokenizer (to split the raw text in tokens), a HashingTF (to transform tokens into hashes) and the Logistic Regression itself (to perform the classification of texts). The Spark DataFrame with the training data is called trainingDF and the one with the test data is called testDF.
In order to do this, they use the following incomplete piece of code: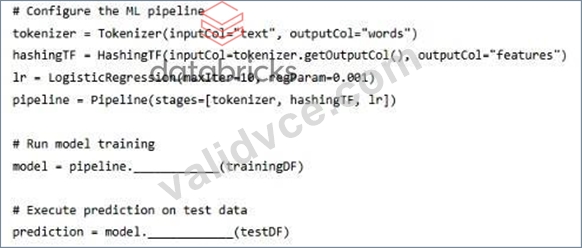
Which option correctly states:
(i) The complete command to run model training;
(ii) The complete command to execute the prediction on test data;
(iii) The object type of the model object returned by the model
training command.
- A.

- B.

- C.

- D.

Answer: C
Explanation:
In Spark MLlib, a Pipeline is trained using the fit method, which applies all estimator stages to the training DataFrame and returns a PipelineModel. Predictions are generated by calling transform on the fitted PipelineModel, which applies the full pipeline (tokenization, feature hashing, and logistic regression) to the test DataFrame.
NEW QUESTION # 131
......
Databricks Databricks-Machine-Learning-Professional Exam Syllabus Topics:
| Topic | Details |
|---|---|
| Topic 1 |
|
| Topic 2 |
|
| Topic 3 |
|
| Topic 4 |
|
| Topic 5 |
|
| Topic 6 |
|
Penetration testers simulate Databricks-Machine-Learning-Professional exam: https://freedumps.validvce.com/Databricks-Machine-Learning-Professional-exam-collection.html